
Elements of a Production-Ready ETL Job with Apache Spark
11 June 2024
|
![]() Inument
Inument

Welcome, data engineers! Today, we’ll dive into elements of a production-ready ETL (Extract, Transform, Load) job with Apache Spark. This ETL job will handle data ingestion from various sources, perform transformations, and manage loading tasks, all while ensuring scalability, reliability, and maintainability.
Introduction to Apache Spark ETL Jobs
Apache Spark is a powerful distributed computing framework that provides high-level APIs in Java, Scala, Python, and R. It excels at processing large datasets efficiently and offers a rich set of libraries and functions for various data processing tasks. Here, we’ll focus on important aspects of building an ETL job using Apache Spark.
Key Components of Spark:
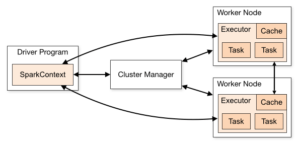
- Spark Cluster: A Spark cluster is a collection of nodes where Spark jobs are executed. It consists of a master node that manages the cluster and worker nodes that execute the jobs. The cluster architecture allows for parallel processing and efficient handling of large-scale data.
- Spark Driver: The Spark Driver is the central process that coordinates the execution of a Spark job. It converts the user’s code into a series of tasks that are distributed across the worker nodes. The driver also keeps track of the execution status and resource allocation.
- Spark Executors: Executors are worker processes that run on the cluster’s worker nodes. They perform the actual computations and store the data needed for the tasks. Each executor is responsible for executing a subset of tasks and reporting the results back to the driver.
- SparkContext: The SparkContext is the main entry point for interacting with Spark functionality. It allows you to create RDDs (Resilient Distributed Datasets), accumulators, and broadcast variables. It also provides configuration options and manages the lifecycle of the Spark application.
Common Project Structure and Dependencies
Spark project consists of several modules organized in a structured manner:
- Common Dependencies: This module contains shared utilities, helper functions, and configuration files that are used across different parts of the project. It ensures consistency and reusability of code.
- ETL Modules: ETL (Extract, Transform, Load) modules implement the logic for data extraction, transformation, and loading. These modules are organized into dedicated functions or classes, making it easier to test and maintain each part of the ETL process independently.
- Environment Configuration: This component stores environment-specific configurations such as database connection strings, API keys, and file paths. It allows the ETL job to adapt to different environments (e.g., development, staging, production) without changing the code.
- Main ETL Job Script: The main ETL job script is the entry point for executing the ETL job. It initializes the Spark context, sets up the necessary configurations, and orchestrates the execution of the ETL modules. This script is typically run using the spark-submit command.
Key Features of the ETL Job:
- Modular Structure: The ETL job is designed with a modular structure, separating the extraction, transformation, and loading steps into dedicated functions or classes. This approach enhances testability and maintainability by allowing each part of the ETL process to be developed and tested independently.
- Dependency Injection: Dependency injection is used to manage object dependencies within the ETL job. This practice improves modularity and testability by decoupling the creation and use of dependent objects, making it easier to swap out implementations for testing or other purposes.
- Delta Lake Integration: Delta Lake is integrated into the ETL job for efficient data storage and management. Delta Lake provides ACID transactions, scalable metadata handling, and data versioning, which help in maintaining data integrity and enabling complex data workflows.
- Integration with External Services: The ETL job integrates with external services such as Redis, ElasticSearch, and others, depending on your use cases. This integration allows for efficient data processing, storage, and retrieval, enabling the ETL job to interact with various data sources and sinks.
- Error Handling and Logging: Robust error handling and logging mechanisms are implemented to ensure better visibility into the ETL job execution. Detailed logs and error messages help in diagnosing and troubleshooting issues, ensuring that the ETL process runs smoothly and reliably.
Crafting a production-ready ETL job with Apache Spark requires careful planning, design, and implementation. By following best practices and leveraging the capabilities of Apache Spark, you can create robust and scalable data processing pipelines that meet the needs of modern data-driven applications.
Remember, this blog provides a foundational overview of Apache Spark ETL jobs. Explore further, experiment with different configurations, and adapt the techniques to suit your specific use cases and requirements.
Happy data engineering!
More articles

Scale Custom AI Agents in 11 Weeks Without System Friction
13 July 2026

Why ‘Move Fast, Break Things’ Is Killing Your Custom AI Agent Development Before Year 2?
19 June 2026
Great Code Isn’t Enough: Why Inument’s AI Staff Augmentation Services Need Strong Communication to Deliver ROI
02 June 2026

Unlocking Business Potential: Scaling with AI Transformation, Not Additional Hirings
13 May 2026
How AI-Driven Platforms are Redefining Creating Intelligence
19 March 2026
0 Comments